Linux 入门笔记
基于Centos7的笔记

Linux Notes
1
export PS1="[3122004716@\h \W]# " # show my stuNum
安装环境
VMware
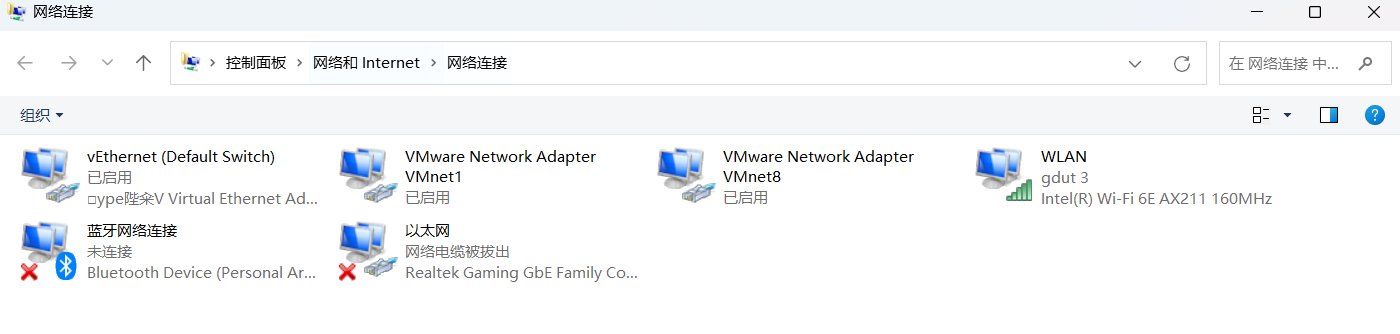
下载安装VMware,网上搜一个激活码,安装后检查确保出现了两个虚拟网卡,如图:
下载CentOS7
下载DVD-2009.iso这个名字的安装包,一般大小是4G。
阿里云镜像下载路径 https://mirrors.aliyun.com/centos/7/isos/x86_64/
官网下载路径 http://isoredirect.centos.org/centos/7/isos/x86_64/
安装CentOS
添加虚拟机 - 自定义- 选择CentOS 7 - 设置服务器配置(2H4G)-选择网络设置
虚拟机网络设置
虚拟机的网络一共有三种模式
- 桥接
- NAT
- 仅主机
根据不同的使用情况选择不同的模式
- 需要访问互联网就选桥接和NAT
- 想和主机在同一个内网,想让内网的其他机器也访问到虚拟机,那就选桥接
- 不上网,那就选仅主机
编辑虚拟机配置,添加ISO文件
进入系统-选第一个安装方式
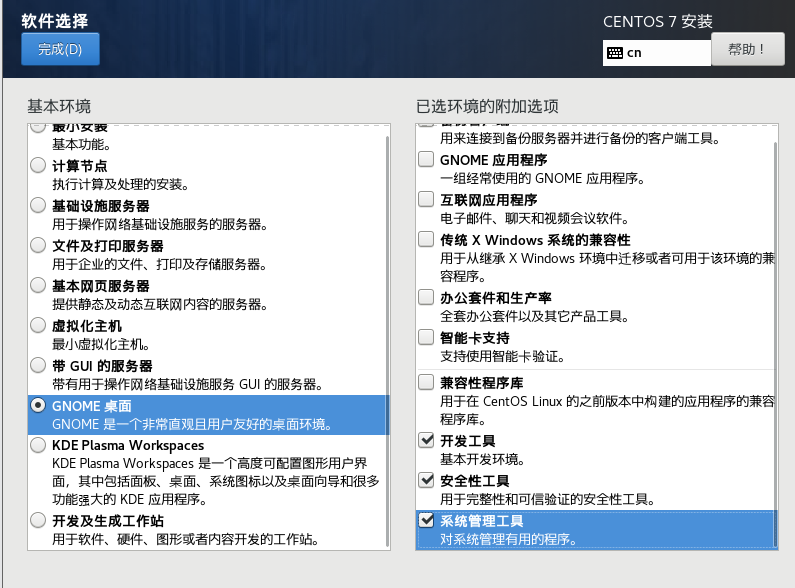
软件安装,选择一个桌面
设置网络
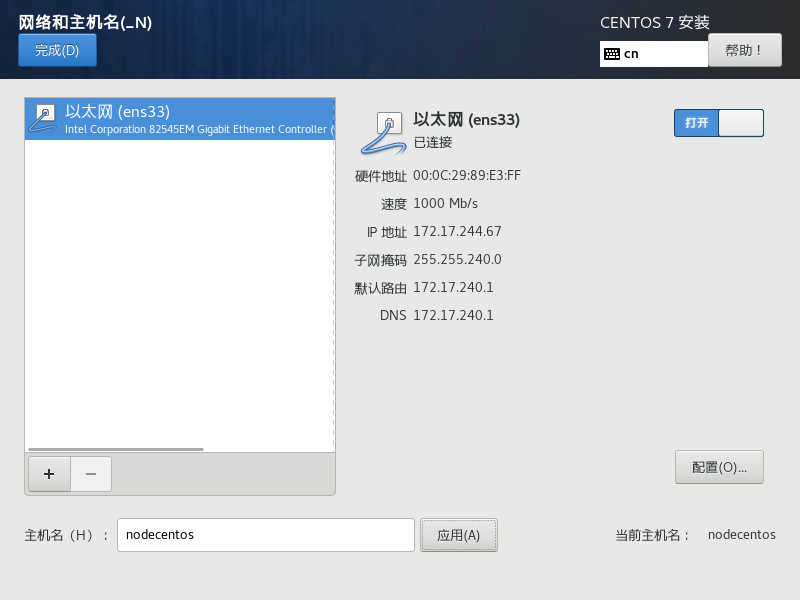
设置密码
Centos@zwei
等待安装:
完成:

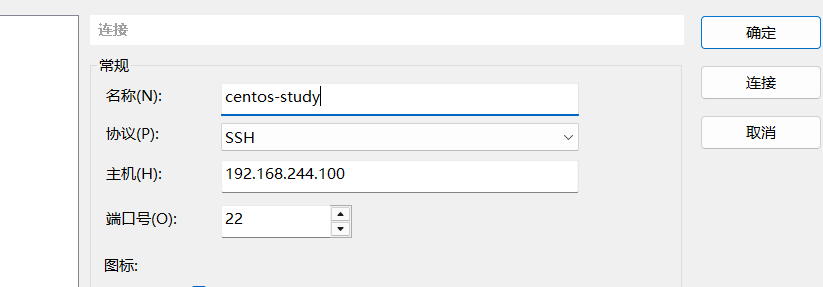
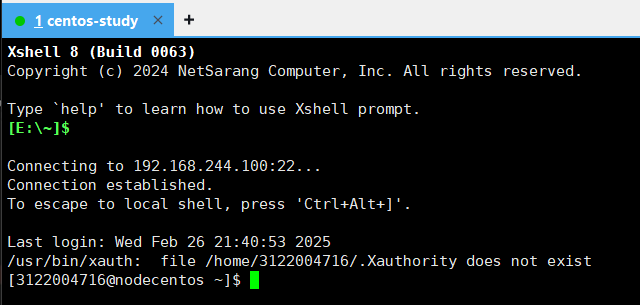
NAT模式,可以用本地SSH工具连接:
命令
Linux基本命令
命令格式 command|[-options] [parameter]
- command:命令,表示要执行的操作,可以是系统命令、自定义命令或别名等
- options:选项,用于指定命令的具体行为或修改其默认行为,通常以单个破折号 - 开头,可以有多个选项,也可以合并在一起
- parameter:参数,用于提供命令操作所需要的具体内容或数据,可以有多个参数,多个参数之间通常以空格分隔
其中 [-options] 、 [parameter]是可选的
举例来说,ls -l /home 命令表示要列出(listing) /home 目录下的文件和子目录,并以长格式显示其详细信息,其中ls是命令, -l 是选项,/home 是参数
各个基础命令如下:
1
2
ls cd pwd mkdir mv rm cat which
find grep wc echo tail vi/vim
-
ls
方式 解释 ls 列出当前工作目录中的所有文件和子目录 ls -a 列出当前工作目录中的所有文件和子目录,包括以.开头隐藏文件 ls -l 以长格式显示当前工作目录中的所有文件和子目录,命令格式也可以缩写为ll ls -a -l -h 以长格式并且人类可读的方式显示当前工作目录中的所有文件和子目录,包括以.开头隐藏文件 -
cd :切换到文件系统的某个目录。
命令 功能 cd ..切换到当前目录的上一级目录 cd ../..切换到当前目录的上两级目录 cd -返回到之前的工作目录 
-
pwd :显示当前工作目录的绝对路径。
-
mkdir :创建目录

-
-p:parents,递归创建目录,若父目录不存在则一同创建例如:
mkdir -p test/hello -
-m:mode,设置创建目录的权限模式
-
-
touch:创建文件
例如:
touch a.txt
-
cp:拷贝
-
-r:recursive,递归复制整个目录树,用于复制目录 -f:force,表示如果目标文件已经存在的话,则强制覆盖目标文件-
\cp强制拷贝,不会提示用户是否覆盖目标文件:\cp a.txt b.txt - 例如:
- a复制一份,叫做b
cp a.txt b.txt - ``cp -r testdir testdir1`
- a复制一份,叫做b
-
复制到指定目录并保持原文件名
1
cp a.txt /path/to/destination/directory/ -
复制到指定目录并修改文件名
1
cp a.txt /path/to/destination/directory/new_name.txt
-
- mv:移动
-
-r:recursive,递归移动,用于移动目录及其下的所有文件和子目录 -
-f:force,强制覆盖目标文件或目录,不会提示用户是否覆盖目标文件 -
例如:
-
mv a.txt testdir -
mv -r test/testdir -
用于文件重命名:
mv a.txt b.txt
-
-
-
rm:删除文件或者目录
-
-r:recursive,递归删除,用于删除目录及其下的所有文件和子目录 -
-f:force,强制删除文件或者目录,没有任何提示 -
例如:
-
rm a.txt -
rm -r test:递归删除整个目录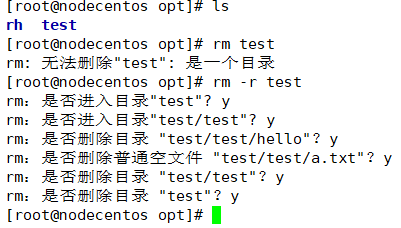
-
rm -rf test:删掉目录或文件没有任何提示
通配符有三种常见类型:
- 星号(*):匹配零个或多个的任意字符。
- 问号(?):匹配任意一个字符,不包括空字符。
- 中括号([]):匹配指定范围内的任意一个字符,也可以用于表示排除范围。
-
-
-
cat 操作文件
cat [选项] [文件名]选项 描述 -nnumber 显示每行的行号(包括空行)。 -bnumber-nonblank 仅对非空行显示行号(忽略空行)。 -Eshow-ends 在每行末尾显示 $符号,用于标识行结束位置。-ssqueeze-blank 将多个连续的空白行压缩成一个空白行。 -A等价于 -vET,显示所有不可见字符(如制表符、换行符等)。-
示例
命令 描述 cat file.txt查看 file.txt文件的内容。cat -n file.txt显示文件内容,并为每一行添加行号(包括空行)。 cat -b file.txt显示文件内容,并为非空行添加行号,忽略空行。 cat -E file.txt在每行末尾显示 $符号,帮助识别行结束位置。cat file1.txt file2.txt > combined.txt将 file1.txt和file2.txt的内容合并,并保存到combined.txt中。cat > newfile.txt创建新文件 newfile.txt,输入内容后按Ctrl+D保存。cat -s file.txt将多个连续的空白行压缩成一个空白行。 


more命令,分页查看文件内容
more file.txt- 按
Enter键逐行滚动。 - 按
Space键逐页滚动。 -
按
q键退出查看。 less命令,分页查看文件内容
less file.txt- 按
j或↓键向下滚动一行。 - 按
k或↑键向上滚动一行。 - 按
Space键向下翻页。 - 按
b键向上翻页。 - 按
/键搜索关键字(例如:/fourth),找到后按n查找下一个匹配项。 - 按
q键退出查看。
-
- which:用于查找并显示指定命令的绝对路径(需要在系统/用户环境变量中),例如:
which python,输出/usr/bin/python
linux系统显示命令
-
uname命令用于查看系统内核的信息
-
hostnamectl命令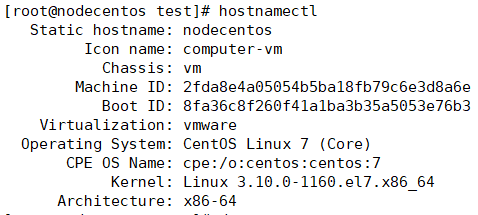
-
date命令,显示计算机当前时间格式:
date [参数] [+日期格式],例如date "+%Y-%m-%d %H:%M:%S"
-
uptime,显示计算机已经启动了多长时间
1 2 3 4 5 6 7 8 9
uptime 17:13:51 up 13 days, 20:38, 4 users, load average: 0.03, 0.08, 0.13 当前时间 运行了多长时间 当前登录用户数 过去1、5、15分钟内可用的系统负载的平均值 uptime -p # 以人类可识别的方式输出系统从开机到到当前的运行时长 up 1 week, 6 days, 20 hours, 41 minutes uptime -s # 以yyyy-mm-dd HH:MM:SS格式输出系统的启动时间 2023-11-23 20:34:55
-
磁盘空间
-
df 以磁盘分区为单位查看文件系统,可以获取硬盘被占用了多少空间,目前还剩下多少空间等信息
-
df -h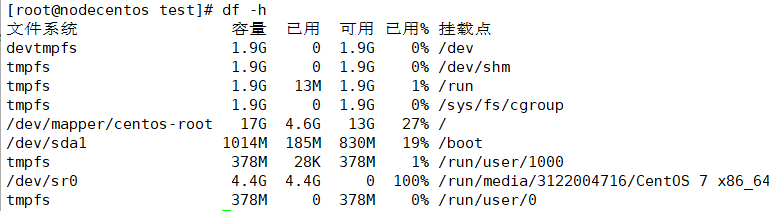
-
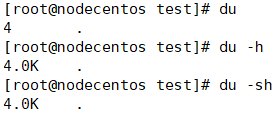
du 的英文原义为 disk usage,含义为显示磁盘空间的使用情况,用于查看当前目录的总大小
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
du -sh # 查看当前目录的大小 274M . du -sh * # 查看当前目录下每个文件的大小 136K api 4.0K cache 32K config 其他参数: -s:对每个Names参数只给出占用的数据块总数。 -a:递归地显示指定目录中各文件及子目录中各文件占用的数据块数。若既不指定-s,也不指定-a,则只显示Names中的每一个目录及其中的各子目录所占的磁盘块数。 -b:以字节为单位列出磁盘空间使用情况(系统默认以k字节为单位)。 -k:以1024字节为单位列出磁盘空间使用情况。 -c:最后再加上一个总计(系统默认设置)。 -l:计算所有的文件大小,对硬链接文件,则计算多次。 -x:跳过在不同文件系统上的目录不予统计。 -h:以K,M,G为单位,提高信息的可读性
-
-
内存
-
free命令是一个用于查看系统内存使用情况的工具
-
echo“echo”是一个常用的Linux命令,可以用于向标准输出或文件写入一行或多行文本。通常用来输出一些提示信息或测试脚本的输出,也可以用于输出变量的值或执行命令的结果
echo [参数] [字符串]-n:不自动换行,输出字符串后不跟随回车符。-e:允许输出字符串中的转义字符,如“\n”表示换行符、“\t”表示制表符等。>echo "Hello World" Hello World >echo -e "Hello World" Hello World >name=zwei >echo $name zwei
-
网络状态命令(会看信息即可)
-
ifconfig
如果没有这个,就安装 net-tools这个软件包,
yum install net-tools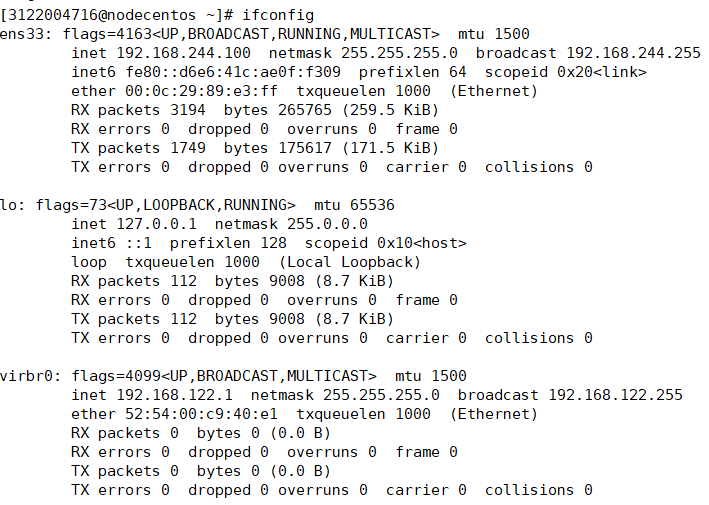
-
ip addr
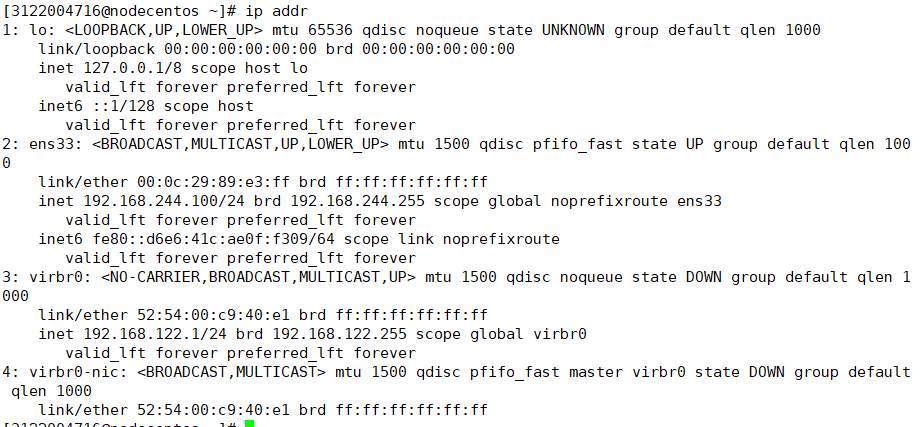
历史命令
history
history 10 # 显示最新执行的10条命令
history -d 1108 # 删除1108行的命令
!历史命令的行号 # 再次执行对应的命令
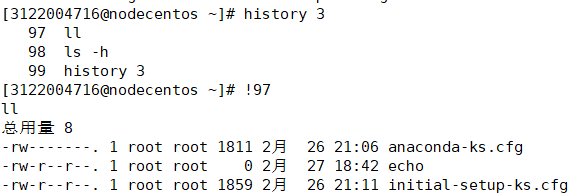
history命令只会记录当前用户的命令历史,而不会记录其他用户执行的命令
另外,历史命令默认只会保存最近执行的1000条命令

软件包管理
不同的Linux发行版,这个命令是不一样的
在 Linux 系统中,不同的发行版使用不同的软件包管理工具。以下是 Debian/Ubuntu 和 CentOS/RHEL 系统中常用的软件包管理命令及其简介:
1. CentOS/RHEL 的软件包管理(yum 或 dnf)
CentOS 和 RHEL(Red Hat Enterprise Linux)系统使用 yum(Yellowdog Updater, Modified)作为默认的软件包管理工具。从 CentOS 8 开始,yum 被 dnf(Dandified Yum)取代,但 yum 仍然是 dnf 的别名,两者命令基本兼容。
常用命令
-
安装软件包
1
yum install 软件包名1
yum install vim -y # -y 表示自动确认安装
- 卸载软件包
1
yum remove 软件包名
1
yum remove vim
- 更新软件包
1 2
yum update 软件包名 # 更新指定软件包 yum update # 更新所有已安装的软件包
- 搜索软件包
1
yum search 关键字
1
yum search vim
- 清理缓存
1
yum clean all # 清理所有缓存 - 生成缓存
1
yum makecache # 生成元数据缓存 - 查看已安装的软件包
1
yum list installed
- 查看软件包信息
1
yum info 软件包名
- 更换软件源
示例:更换为阿里云的 CentOS 7 源
1 2
curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo yum makecache
2. Debian/Ubuntu 的软件包管理(apt 或 apt-get)
Debian 和 Ubuntu 系统使用 apt(Advanced Package Tool)作为默认的软件包管理工具。apt 是 apt-get 的改进版本,提供了更友好的用户界面。
常用命令
- 安装软件包
1
apt install 软件包名1
apt install vim -y # -y 表示自动确认安装
- 卸载软件包
1 2
apt remove 软件包名 # 卸载软件包但保留配置文件 apt purge 软件包名 # 卸载软件包并删除配置文件
1
apt remove vim
-
更新软件包
1 2 3
apt update # 更新软件包列表 apt upgrade # 升级所有已安装的软件包 apt full-upgrade # 升级并处理依赖关系(可能删除旧包)
- 搜索软件包
1
apt search 关键字
1
apt search vim
- 清理缓存
1 2
apt clean # 清理所有已下载的软件包 apt autoclean # 清理过时的软件包
- 查看已安装的软件包
1
apt list --installed - 查看软件包信息
1
apt show 软件包名
-
更换软件源 编辑
/etc/apt/sources.list文件,替换为新的源地址。 示例:更换为阿里云的 Ubuntu 源1 2
sudo sed -i 's|http://archive.ubuntu.com|https://mirrors.aliyun.com|g' /etc/apt/sources.list sudo apt update
文件传输命令
scp
SCP命令是基于SSH协议的命令行工具,用于在不同操作系统之间快速、安全地传输文件。只需打开终端并输入SCP命令即可开始使用它
# 将当前主机的xx文件传输到目标主机的目标目录上去
scp 文件名称 root@目标主机:目标目录
# 例如,192.168.244.131 传到 192.168.244.100
scp mykali.txt [email protected]:/opt/test
# 将目标主机的文件下载到当前主机的xx目录
scp root@目标主机:目标目录 文件目录
# 例如:192.168.244.100 下载 192.168.244.131 的文件
scp [email protected]:/opt/test/mykali.txt mykali.txt

一些常用的参数
-F:指定ssh配置文件
-i:identity_file 从指定文件中读取传输时使用的密钥文件,此参数直接传递给ssh
-o:指定使用的ssh选项
-P:指定远程主机的端口号
-p:保留文件的最后修改时间,最后访问时间和权限模式
-q:不显示复制进度
-r:以递归方式复制
重启,关机命令
# 关机
shutdown -h now
init 0
# 重启
shutdown -r now
reboot
文件与目录命令
1. more 命令
more 命令用于分页显示文件内容,适合逐页阅读。
常用参数:
+n:从第n行开始显示。-n:定义屏幕大小为n行。+/pattern:在每个文件显示前搜索指定字符串,并从该字符串前两行之后开始显示。-c:从顶部清屏,然后显示。
操作键:
- 空格键:下一页。
- 回车键:下一行。
- b:上一页。
示例:
1
2
3
more +10 myfile.txt # 从第10行开始显示文件内容
more -20 myfile.txt # 每页显示20行
more +/search myfile.txt # 搜索 "search" 并从匹配处开始显示
2. less 命令
less 是比 more 更强大的分页工具,支持向前和向后翻页,以及搜索功能。
常用参数:
-e:文件显示结束后自动退出。-g:只标志最后搜索的关键词。-i:忽略搜索时的大小写。-m:显示类似more的百分比。-N:显示每行的行号。
操作键:
- 空格键:下一页。
- 回车键:下一行。
- ↓:向下翻一页。
- ↑:向上翻一页。
- /字符串:向下搜索字符串。
- ?字符串:向上搜索字符串。
示例:
1
2
less -N myfile.txt # 显示文件内容并显示行号
less +/search myfile.txt # 搜索 "search" 并从匹配处开始显示
3. head 命令
head 命令用于显示文件的前几行,默认显示前10行。(可操作多个文件)
1
head [OPTIONS] [FILE-1] [FILE-2] ..
常用参数:
-n 数字:显示前n行。-n -数字:跳过文件的最后n行。-c 数字:显示前n个字符。-c -数字:跳过最后n个字符。-v:显示文件名。-q:不显示文件名(默认显示)。
示例:
1
2
head -n 5 myfile.txt # 显示文件前5行
head -c 100 myfile.txt # 显示文件前100个字符
4. tail 命令
tail 命令用于显示文件的最后几行,默认显示最后10行。
常用参数:
-n 数字:显示最后n行。-f:持续追踪文件内容(常用于查看日志)。-n +数字:从第n行开始显示到文件末尾。
示例:
1
2
tail -n 20 myfile.txt # 显示文件最后20行
tail -f myfile.log # 持续追踪日志文件
5. wc 命令
wc 命令用于统计文件的字节数、字符数、行数和单词数。
常用参数:
-c:输出字节数统计。-m:输出字符数统计。-l:输出行数统计。-w:输出单词数统计。-L:显示最长行的长度。
示例:
1
2
wc -l myfile.txt # 统计文件行数
wc -w myfile.txt # 统计文件单词数

6. diff 命令
diff 命令用于比较两个文件的差异(文件1如何才能变成文件2)。
语法:
1
diff 文件1 文件2
输出说明:
c:表示需要修改。a:表示需要添加。d:表示需要删除。<:表示第一个文件的内容。>:表示第二个文件的内容。
示例:
文件 1:file1.txt
1
2
3
4
5
6
7
Line 1
Line 2
Line 3
Line 4
Line 5
Line 6
:wq
文件 2:file2.txt
1
2
3
Line 6
Line 7
Line 8
使用 diff 命令比较
1
diff file1.txt file2.txt
输出结果

1,5d0:- 表示第一个文件(
file1.txt)的第1行到第5行需要被删除。 < Line 1到< Line 5:显示第一个文件中被删除的内容。
- 表示第一个文件(
6a7,8:- 表示在第一个文件的第6行之后,需要添加第二个文件(
file2.txt)的第7行到第8行。 > Line 7和> Line 8:显示第二个文件中需要添加的内容。
- 表示在第一个文件的第6行之后,需要添加第二个文件(
- 出现
c表示变化,比如3c3,第三行有变化
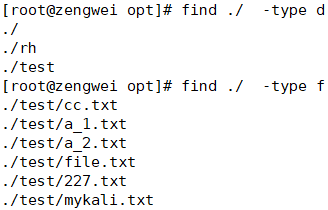
7. find 命令
find 命令用于在指定路径下搜索文件。
语法:
1
find 搜索路径 [选项] 搜索内容
常用参数:
-name:按文件名搜索。-iname:按文件名搜索,不区分大小写。-size [+|-]大小:按文件大小搜索。-mtime [+|-]时间:按文件修改时间搜索。-type d:查找目录。-type f:查找普通文件。
示例:
按照文件名搜索
1
find . -name "*.txt" # 查找当前目录下所有 .txt 文件

可以使用 ll -h查看文件大小
1
ll -h /opt/test/a_1.txt
按照修改时间搜索
- Linux中的文件有访问时间(atime)、数据修改时间(mtime)、状态修改时间(ctime)这三个时间,我们也可以按照时间来搜索文件。
1
2
3
find ./ -mtime -1 # 搜索一天内修改的文件
find ./ -mtime 5 # 搜索5-6天,那天修改的文件
find ./ -atime -7 # atime是访问时间

按照大小搜索
1
find . -size -100M # 查找当前目录下小于100M的文件
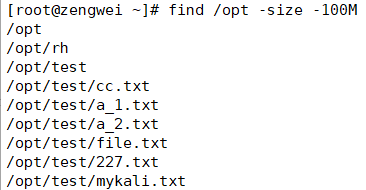
按照文件类型搜索
1
2
3
4
find ./ -type d # 查找当前文件中的目录
find ./ -mtime 5 -type d # 搜索5-6天,那天修改的目录
d是目录,f是文件
逻辑运算符
1
2
3
-a :and逻辑与,不能连接两个相同约束条件(可以省略)
-o :or逻辑或
-not :not 逻辑非
例如:
1
find . -type f \( -name "*1.txt" -o -name "*2.txt" \)
查找当前目录下 *1.txt 或者 *2.txt
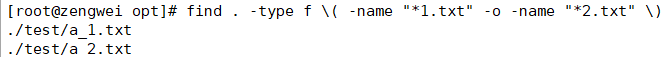
1
find /opt -type f -name "*.txt" -a -size -1k
查找 /opt 目录下 .txt 文件且小于1k

文件权限与属性命令
文件权限:
-
rwx:可读、可写、可执行(对应数字421,-对应0)。因此,
rwx可以表示为 4+2+1 = 7,r-x可以表示为 4+0+1 = 5,r--可以表示为 4+0+0 = 4,--x可以表示为 0+0+1 = 1,---可以表示为 0。例如,权限
rwxr-xr--可以表示为数字754。
| 文件权限 | 针对文件 | 针对目录 |
|---|---|---|
| r 读权限 | 是否可以查看文件内容 | 是否能够列出ls目录内容 |
| w 写权限 | 是否可以编辑文件内容 | 是否能够创建、删除、复制、移动文档 |
| x执行权限 | 可执行权限就是能够执行该文件 | 是否可以进入目录和获得目录下文件的列表,要对目录下存在的文件进行读取和修改,必须要能进入目录,所以目录必须要有执行权限 |
文件属性:
例如:-rwxr-xr-x 2 root root 83 Mar 2 18:35 appveyor
权限信息的组成
权限信息由 10 个字符组成,可以分为以下几个部分:
- 文件类型(第 1 个字符)
-:普通文件d:目录l:符号链接c:字符设备文件b:块设备文件p:命名管道(FIFO)s:套接字文件
- 权限(第 2-10 个字符)
- 这 9 个字符分为三组,每组 3 个字符,分别表示文件所有者(User)、所属组(Group)和其他用户(Others)的权限。
- 每组的 3 个字符分别表示:
r:读权限(Read)w:写权限(Write)x:执行权限(Execute)-:表示没有该权限
ls -l 示例输出:
没有修改权限时:

- 你使用
vi打开了一个只读文件。 - 你尝试进行了一些修改,但无法保存。
- 你看到了 “E45: 已设定选项 ‘readonly’ (请加 ! 强制执行)” 错误。
- 你输入
:q!并按下回车键。 vi编辑器会立即退出,并且你所做的任何修改都会被丢弃。
chmod 命令
chmod 命令用于更改文件权限。
1
chmod [选项] 权限 文件
常用参数:
- 数字形式:
1
chmod 755 227.txt # 设置文件权限为 rwxr-xr-x


-
字符形式:
1 2 3 4 5 6 7 8 9 10 11 12
u 表示文件属主用户(user) g 表示组用户 (group) o 表示其它人 (other) a 表示全部 (all,默认值) r 读 w 写 x 执行 + 表示新增 - 表示删除 = 表示设置
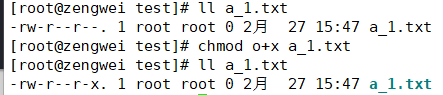
1 2
chmod o+x a_1.txt # 给o(其他人)添加可执行权限 chmod o=rwx a_1.txt # 给o(其他人)rwx权限
一个常用命令:
1
chmod +x main #这就是给全部用户追加可执行权限
chown 命令
chown 命令用于更改文件的属主和属组。
1
chown [选项] 属主:属组 文件
示例:
1
2
3
4
chown root main.java # 将main文件的属主修改为root
chown root:root myfile.txt # 将文件属主和属组改为 root
chown -R root:root mydir # 递归修改目录下所有文件的属主和属组
chown -R root dist # 把dist目录下的所有文件同等设置属主
wget 命令
wget 是 Linux 下的文件下载工具,用法是 wget [选项] [URL]。

用法示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
wget http://example.com/file.zip # 下载文件
wget -O myfile.zip http://example.com/file.zip # 指定保存文件名
wget -b https://example.com/file.zip #后台下载
wget -c https://example.com/file.zip #断点续传,如果下载中断,可以使用 -c 选项继续下载未完成的部分
wget -r -l 2 https://example.com #递归下载 https://example.com 网站的内容,-l 2 表示下载深度为 2 层。(请谨慎使用此选项,避免对服务器造成过大压力)
wget -e "http_proxy=http://proxy_ip:proxy_port" https://example.com/file.zip # 使用指定的 HTTP 代理服务器下载文件。
wget -U "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36" https://example.com/file.zip # 设置 User-Agent
wget -i urls.txt # 下载多个文件: 将多个 URL 写入一个文本文件(例如 urls.txt),然后使用 -i 选项下载
wget --no-check-certificate https://example.com/file.zip # 跳过 SSL 证书验证
Linux文件系统
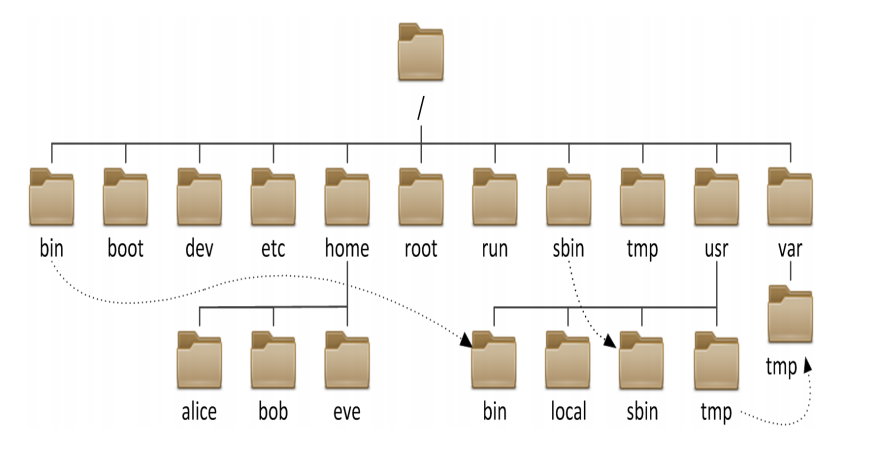
在Linux中,一切皆文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
/ - 根目录,整个文件系统层次结构的根目录,所有内容都位于此目录下。
/bin - 存放基本的可执行的程序(二进制文件),包括最基本的命令,如ls和cp。
/boot - 包含内核引导加载程序文件。
/dev - 存放设备文件。
/etc - 核心系统配置目录,应该只保存配置文件。
/home - 用户的主目录,保存你的文档,文件,设置等。
/lib、/lib32、/lib64、/libx32
- 主要目的是存放特定的库,这些库是在/bin和/sbin目录里的工具所需要的库,/lib中的库可以是32位或64位
/lost+found - 这个目录一般情况下是空的,当系统非法关机后,如果你丢失了一些文件,在这里能找回来,通常很少用到此目录
/media - 用作可移动媒体的连接点,如USB驱动器。
/mnt - 临时挂载的文件系统。
/opt - 可选应用软件包。
/proc - 当前运行进程的信息。
/root - root用户的主目录。
/run - 自上次引导以来运行系统的信息。
/sbin - 包含基本的系统二进制文件,通常只能由root用户运行。
/srv - 系统提供的特定于站点的数据。
/tmp - 临时文件的存储
/usr - 通常它不包含主文件夹意义上的用户文件。这意味着用户安装的软件和实用程序,但这并不是说你不能在那里添加个人目录。在这个目录中有/usr/bin、/usr/local等子目录。
/var - 变量目录,用于系统日志记录、用户跟踪、缓存等。
相对路径和绝对路径
极其重要,web开发中的路径同样适用
-
绝对路径:指文件在文件系统中的准确位置。通常在本地主机上,以根目录为起点 exp:
/opt/test/file.txt -
相对路径:指相对于用户当前位置的一个文件或目录的位置
1 2 3 4 5 6
exp1: 假设你当前位于 `/usr/bin` 目录,要进入 `/opt/test` 目录,可以执行以下命令: cd ../../opt/test exp2: 假设你当前位于 `/usr` 目录,要进入 `/opt/test` 目录,可以执行以下命令: cd ../opt/test
软硬链接
软链接
它的功能是为某一个文件在另外一个位置建立一个同步的链接,访问它等于访问源文件。可以理解成Windows中的快捷方式
ln -s 真实的文件 软链接路径 #新建软链接
删除源文件,软链接就无法正常使用了

硬链接
多个文件名指向同一个物理文件
ln 真实的文件 硬链接路径 #新建硬链接
有个备份效果,删除源文件,硬链接的文件还能用
# 如果你链接的还是一个软连接,那实际还是软链接
其他参数
-f : 链结时先将与 dist 同档名的档案删除
-i : 在删除与 dist 同档名的档案时先进行询问
-s : 进行软链结(symbolic link)
-v : 在连结之前显示其档名
Vim 文本编辑器
一般来说,vi命令是有的,vim可能没有
没有的话,就使用 yum install -y vim 或 apt-get install vim 进行安装即可
vim的工作模式有三种
命令模式
命令模式是通过vim指令进入操作的默认模式,可以切换成其他模式,另外的模式进行切换也需要命令模式作为中间模式。
记一些常用操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
yy 复制光标所在行
p 粘贴剪贴板的内容,在当前行后面新增一行
dd 删除所选行
x 删除光标所在位置的字符
u 撤销上次的操作
ctrl r 撤销撤销的操作
shift g 最后一行开头
gg 文档内容的开头
shift 4 a 当前行行尾
shift 6 当前行行首
w 向后移动一个单词的位置
b 向前移动一个单词的位置
(如果没有方向键的话)
h 向左
j 向下
k 向上
l 向右
插入模式(输入内容时,一半是插入模式)
通过在命令模式,按键i/a/o切换而来
i 光标不会移动
a 光标向后移动一个字符的位置,按Esc退出该模式后光标会向前挪一个字符的位置
o 会伴随有新起一行的操作,按Esc退出该模式后换行的操作仍不会撤销
退出插入模式,按esc即可,或者ctrl+C
底行模式
通过在命令模式,输入:得到
set nu / set nonu 显示或去掉行号
(数字) 定位到某一行
wq! 保存并强制退出
进程管理
什么是进程
在Linux中,进程(Process)是指正在运行的程序实例。一个进程可以看做是系统中的一个任务,它可以执行各种操作,例如打开文件、发送网络请求、计算数据等。每个进程都有自己独立的内存空间和资源使用情况
每个进程都有一个唯一的进程ID(PID),它是一个非负整数,用于标识进程。除了PID外,每个进程还有其他属性,如父进程ID、进程状态、进程优先级、内存使用情况等。
Linux系统中有许多命令和工具可以用来管理和监视进程,例如ps、top、kill等
其中,ps命令可以列出当前系统中所有进程的详细信息,包括进程名、PID、状态、CPU占用率等
top命令可以实时显示系统中各个进程的资源使用情况,帮助用户进行性能监控和故障排除
kill命令可以用来停止某个进程的运行。
后台执行
这里有一个打印当前时间的脚本,用于练习程序后台执行;
执行sh脚本,有两种方式
-
sh xxx.sh -
先
chmod +x xxx.sh赋予可执行权限,然后执行:./xxx.sh
#!/bin/bash
# 设置文件路径
output_file="date.log"
# 无限循环,每隔一秒执行一次
while true; do
# 获取当前时间,并格式化为小时:分钟:秒
current_time=$(date "+%H:%M:%S")
# 打印当前时间到终端
echo "当前时间: $current_time"
# 将当前时间追加到文件
echo "$current_time" >> "$output_file"
# 等待一秒钟
sleep 1
done
& 的作用
& 符号用于将一个命令放入后台执行。 放入后台的进程不会阻塞当前终端,你可以继续执行其他命令。
最好是将输出的内容重定向到文件中
./print_time.sh & # 这条命令将 print_time.sh 脚本放入后台运行。脚本的标准输出仍然会输出到当前终端。
./print_time.sh > out.log & # 脚本放入后台运行,并且将脚本的标准输出重定向到 out.log 文件。常用,适合需要长时间运行,记录输出,不希望干扰终端的情况
-

[1] 32185: 这表示:[1]: 这是 作业编号 (job ID) 。 每个放入后台运行的进程都会被分配一个作业编号。 你可以使用jobs命令查看所有后台作业及其编号。32185: 这是进程 ID (PID) 。 这是操作系统分配给data.sh进程的唯一标识符。 你可以使用ps -ef | grep data.sh来查找和kill这个进程。
nohup 命令
nohup是”No Hang Up”的缩写,意思是不挂断,即使退出终端或外壳程序也可以保持进程运行
nohup ./print_time.sh &
它会默认生成一个nohup.out日志文件
systemctl 命令
systemctl 是 Linux 系统中用于管理 systemd 服务的核心命令。systemd 是现代 Linux 系统中最主要的系统和服务管理器,它负责启动、停止、重启、监控系统服务,以及管理系统启动过程。
- 现代 Linux 发行版广泛使用:
systemd已经取代了SysVinit,成为大多数 Linux 发行版(如 Ubuntu, Fedora, CentOS/RHEL 7 及以上版本)的默认系统和服务管理器。 - 服务管理: 可以轻松地启动、停止、重启、重新加载、查看服务的状态。
- 开机启动管理: 可以方便地设置服务是否开机自启动。
- 依赖管理:
systemd能够处理服务间的依赖关系,确保服务按照正确的顺序启动和停止。 - 日志管理:
systemd集成了日志管理功能,方便查看服务日志。
systemctl 的基本用法:
systemctl 命令的基本语法如下:
1
systemctl [选项] 命令 [服务名称]
- 选项: 控制
systemctl行为的选项,如--system(管理系统服务) 和--user(管理用户服务)。 - 命令: 要执行的操作,如
start,stop,restart,status,enable,disable等。 - 服务名称: 要管理的服务单元的名称,通常以
.service结尾 (可以省略.service后缀)。
常用命令及其示例:
-
启动服务:start
示例:启动 Apache Web 服务器
1
sudo systemctl start apache2 -
停止服务:stop
示例:停止 Nginx Web 服务器
1
sudo systemctl stop nginx -
重启服务:restart
示例:重启 SSH 服务
1
sudo systemctl restart ssh -
重新加载服务配置:reload
示例:重新加载 systemd-resolved 服务配置
1
sudo systemctl reload systemd-resolvedreload和restart的区别在于,reload通常用于在不中断服务的情况下应用新的配置。 并非所有服务都支持reload操作。
-
查看服务状态:status
示例:查看 Docker 服务状态
1
systemctl status docker
systemctl status命令会显示服务的详细信息,包括服务的状态(running, stopped, failed 等)、进程 ID、日志信息等。 -
设置开机自启动:enable
示例:设置 MySQL 服务开机自启动
1
sudo systemctl enable mysql
-
取消开机自启动:disable
示例:取消 PostgreSQL 服务开机自启动
1
sudo systemctl disable postgresql -
查看服务是否开机自启动:
示例:查看 Firewalld 服务是否开机自启动
1
systemctl is-enabled firewalld
该命令会输出
enabled或disabled。 -
列出所有服务单元:
1
systemctl list-units --type=service
该命令会列出所有已加载的服务单元,包括它们的状态。
-
列出所有已启动的服务单元:
1
systemctl list-units --type=service --state=running
-
查看服务单元文件:
服务单元文件包含了服务的配置信息。 服务单元文件通常位于
/lib/systemd/system/或/etc/systemd/system/目录下。1
cat /lib/systemd/system/服务名称.service
示例:查看 ssh 服务的单元文件
1
cat /lib/systemd/system/ssh.service注意: 不要直接修改
/lib/systemd/system/目录下的服务单元文件,如果需要修改,应该将文件复制到/etc/systemd/system/目录下进行修改。
管理远程主机上的服务:
可以使用 -H 选项管理远程主机上的服务。
1
systemctl -H 用户名@主机名 命令 服务名称
示例:在远程主机 192.168.1.100 上启动 Apache 服务:
1
systemctl -H [email protected] start apache2
用户服务与系统服务:
- 用户服务: 用户服务由特定用户管理,通常在用户登录后启动,用户退出后停止。 用户服务的单元文件通常位于
~/.config/systemd/user/目录下。 使用--user选项管理用户服务。 - 系统服务: 系统服务由 root 用户管理,在系统启动时启动,在系统关闭时停止。 系统服务的单元文件通常位于
/lib/systemd/system/或/etc/systemd/system/目录下。 使用--system选项或省略选项管理系统服务。
重要事项:
- 权限: 大多数管理系统服务的
systemctl命令都需要sudo权限。 - 服务单元文件:
systemd使用服务单元文件来定义服务的配置信息。 服务单元文件是纯文本文件,可以使用任何文本编辑器打开和编辑。
更多 systemctl 资料:
-
https://blog.csdn.net/Dayu_log/article/details/129009345
-
https://blog.csdn.net/weixin_53064820/article/details/127539019
ps命令 查看进程
单独使用 ps 命令,不带任何选项,会显示当前用户在当前终端/会话中运行的进程。
查看全部的进程
ps aux
-a 选项指示 ps 显示来自所有用户的所有进程,但是这排除了与特定终端相关联的进程
-u 选项表示面向用户的格式,它提供与正在运行的进程相关的更详细的信息
-x 选项列出了通常在系统引导时启动的进程以及后台进程
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 2 0.0 0.0 0 0 ? S Jan17 0:00 [kthreadd]
- USER – 运行进程的用户
- PID – 进程 ID
- %CPU – CPU 使用率百分比
- %MEM – 物理内存占用的百分比
- VSZ – 千字节为单位的每个进程的虚拟内存大小
- RSS – 使用的物理内存的大小
- STAT – 进程状态代码 S (sleeping), Z (zombie) and R (Running)
- START – 进程开始运行的时间
根据用户查进程
id 用户名 # 获取用户id
ps -u 用户id
ps -u 用户名
使用 PID 和 PPID 显示进程
ps -fp PID
使用进程名查进程
ps -C 进程名
不过这个查询很迷
还是 grep来的实在一点
ps aux | grep 进程名

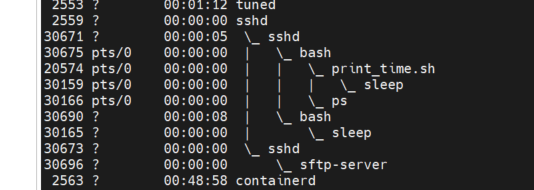
打印流程树
ps -e --forest
进程树显示了 Linux 系统中进程是如何链接的
实时进程监控
可以使用 watch 实用程序监视进程的静态信息。输出每秒钟更新一次,如下所示
watch -n 1 'ps -eo pid,ppid,cmd,%mem,%cpu --sort=-%cpu | head'
列出消耗高内存的顶级进程
ps -eo pid,ppid,cmd,%mem,%cpu --sort=-%mem | head
列出消耗高 cpu 的顶级进程
ps -eo pid,ppid,cmd,%mem,%cpu --sort=-%mem | head
显示进程运行的持续时间
ps -eo comm,etime,user
结束进程 kill命令
kill 命令会向操作系统内核发送一个信号(多是终止信号)和目标进程的 PID,然后系统内核根据收到的信号类型,对指定进程进行相应的操作
kill 命令是按照 PID 来确定进程的,所以 kill 命令只能识别 PID,而不能识别进程名

| 信号编号 | 信号名 | 含义 |
|---|---|---|
| 0 | EXIT | 程序退出时收到该信息。 |
| 1 | HUP | 挂掉电话线或终端连接的挂起信号,这个信号也会造成某些进程在没有终止的情况下重新初始化。 |
| 2 | INT | 表示结束进程,但并不是强制性的,常用的 “Ctrl+C” 组合键发出就是一个 kill -2 的信号。 |
| 3 | QUIT | 退出 |
| 9 <常用> | KILL | 杀死进程,即强制结束进程。 |
| 11 | SEGV | 段错误。 |
| 15 | TERM | 正常结束进程,是 kill 命令的默认信号。 |

pkill
pkill 命令常用选项和示例
| 选项 | 描述 | 示例 | 说明 |
|---|---|---|---|
| (无选项) | 默认行为:发送 TERM 信号 (15) 到匹配进程。 |
pkill firefox |
正常结束所有名为 firefox 的进程。 |
-信号 或 -s 信号 |
指定要发送的信号。与kill命令相同 |
pkill -9 firefox 或 pkill -KILL firefox |
强制结束所有名为 firefox 的进程。 |
-u 用户名 |
只匹配指定用户的进程。 | pkill -u zhangsan firefox |
正常结束用户 zhangsan 运行的所有 firefox 进程。 |
-x |
精确匹配进程名。 | pkill -x "my_exact_process_name" |
结束进程名称完全匹配 "my_exact_process_name" 的进程。 |
-f |
匹配完整的命令行,而不仅仅是进程名。 | pkill -f "python my_script.py --option value" |
结束执行命令 python my_script.py --option value 的进程。 |
-i |
忽略大小写。 | pkill -i FireFox |
结束进程名包含 “FireFox” (不区分大小写) 的进程。 |
-n |
仅杀死匹配到的最近启动的进程. | pkill -n firefox |
结束最近启动的名为 firefox 的进程。 |
-o |
仅杀死匹配到的最老启动的进程. | pkill -o firefox |
结束最老启动的名为 firefox 的进程。 |
-c |
搭配-n或-o, 只匹配具有相同command line的进程。 |
pkill -n -c "python my_script.py" |
结束command line完全匹配” python my_script.py “的最近启动的进程 |
-U 用户ID |
指定用户ID匹配进程。 | pkill -U 1000 firefox |
结束用户ID为1000的所拥有的 firefox 进程。 |
-G 组ID |
指定组ID匹配进程。 | pkill -G 100 firefox |
结束组ID为100所有的 firefox 进程。 |
--help |
显示帮助信息。 | pkill --help |
显示 pkill 命令的用法和选项说明。 |
--version |
显示版本信息。 | pkill --version |
显示 pkill 命令的版本号。 |
使用示例说明:
- 基本用法:
pkill 进程名是最常用的方式,它会尝试正常结束所有匹配该进程名的进程。 - 强制结束: 使用
-9(或-KILL) 选项可以强制结束进程。 但务必谨慎,因为强制结束可能导致数据丢失。 - 用户限定: 使用
-u 用户名选项可以只结束特定用户运行的进程。 这在多用户系统中非常有用。 - 精确匹配: 使用
-x选项可以确保只结束进程名完全匹配的进程。 这可以避免误杀进程。 - 完整命令行匹配:
-f选项非常强大,可以根据进程的完整命令行来匹配进程。 这对于结束执行特定命令的进程非常有用。例如可以结束后台运行的某个特定脚本。
系统进程监控 top命令
top命令用于实时监测系统资源使用状况,包含,进程、cpu,内存等
常用参数
top:启动top命令
top -c:显示完整的命令行
top -b:以批处理模式显示程序信息
top -S:以累积模式显示程序信息
top -n 2:表示更新两次后终止更新显示
top -d 3:设置信息更新周期为3秒
top -p 139:显示进程号为139的进程信息,CPU、内存占用率等
top -n 10:显示更新十次后退出
表头内容含义
PID
USER
PR Priority Value
NI nice value,通过程序给进程设置的,数值越小,用户空间优先级越高
VIRT 进程使用的虚拟内存的大小,单位是KiB。
RES 常驻内存的内存大小,单位是KiB。
SHR 共享内存的大小,单位是KiB。
S 表示进程的状态,有一下几个状态。
%CPU 上次一刷新之前对应的进程对CPU的占有率
%MEM 这个主要是进程使用的内存占用实际的可用的物理内存的比例
TIME+ 这个表示自从进程启动以来累计消耗的CPU时间
COMMAND 启动进程的时候执行的命令

top 命令中 PR (Priority) 值的含义
| PR 值范围 | 含义 |
|---|---|
| 0 到 39 | 普通进程(非实时进程),数值越低,优先级越高(与 NI 共同决定)。 |
| RT 或负值(如 -2) | 实时进程(Real-time Process),优先级高于所有普通进程。 |
用户管理
Linux基于用户身份对资源访问进行控制
用户账号的分类
-
超级用户:root用户是Linux操作系统中默认的超级用户账号,对本主机拥有最高的权限,系统中超级用户是唯一的。
-
普通用户:由root用户或其他管理员用户创建,拥有的权限会受到限制,一般只在用户自己的宿主目录中拥有完整权限。
-
程序用户:在安装Linux操作系统及部分应用程序时,会添加一些特定的低权限用户账号,这些用户一般不允许登录到系统,仅用于维持系统或某个程序的正常运行,如bin、daemon、ftp、mail等。
默认的创建用户
1
useradd xxx
可以使用 passwd给用户设置密码
| 选项 | 介绍 |
|---|---|
| -D | 改变新建用户的预设值 |
| -c | 添加备注文字 |
| -d | 新用户每次登陆时所使用的家目录 |
| -e | 用户终止日期,日期的格式为YYYY-MM-DD |
| -f | 用户过期几日后永久停权。当值为0时用户立即被停权,而值为-1时则关闭此功能,预设值为-1 |
| -g | 指定用户对应的用户组,例如:useradd -g root r1 |
| -G | 定义附加的用户组 |
| -m | 用户目录不存在时则自动创建 |
| -M | 不建立用户家目录,优先于/etc/login.defs文件设定 |
| -n | 取消建立以用户名称为名的群组 |
| -r | 建立系统帐号 |
| -s | 登录的shell |
| -u | 指定用户id |
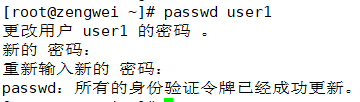
- useradd
- 设置密码
- SSH登录
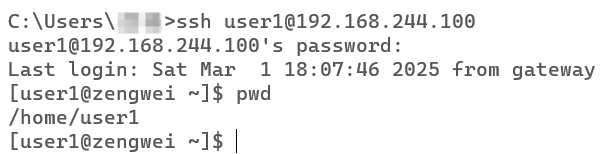
设置用户默认的shell
1
2
3
useradd -s /bin/bash xxx
不让用户远程登录
useradd -s /sbin/nologin xxx
指定用户组
通常,创建新用户时,会创建与该用户同名的组,新用户被添加为此组的成员
1
useradd -g 已存在的组名 new_username

查看用户信息id
用于显示当前登录用户的UID(用户标识符)和GID(组标识符)
id # 显示当前用户的
id user1 # 显示指定用户的
id root
uid=0(root) gid=0(root) groups=0(root)

相关用户密码
/etc/passwd 文件
在 Linux 系统中,每个用户都有一个对应的 /etc/passwd 文件中的记录行。这个文件对所有用户都是可读的,它记录了每个用户的一些基本属性信息。
1
2
3
4
5
cat /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
...
查看 /etc/passwd:
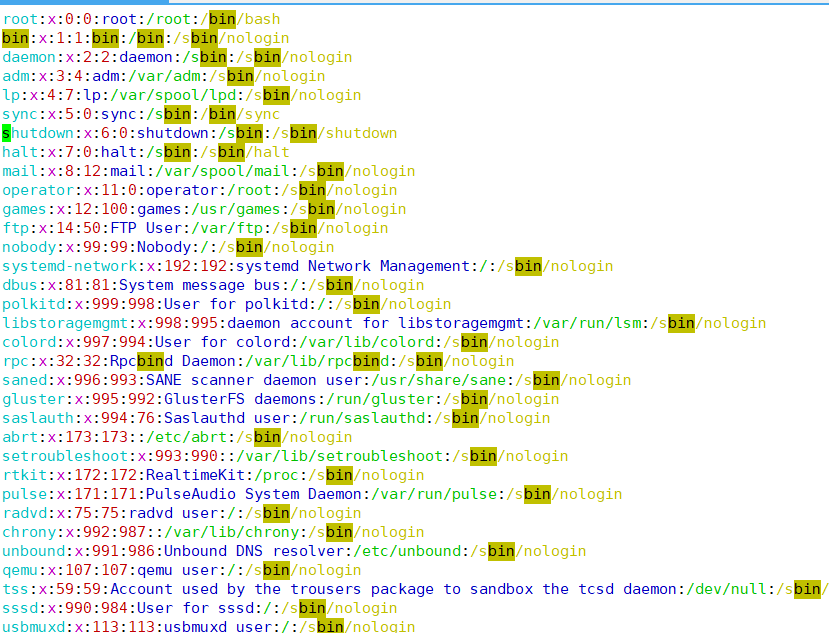
-
大多数是
nologin不能登录的 -
以下是一个具体的
/etc/passwd示例行及其字段解析:1
root:x:0:0:root:/root:/bin/bash
字段 示例值 含义 用户名 root超级用户的名称。 密码占位符 x密码hash存储在 /etc/shadow文件中。用户 ID (UID) 0超级用户的 UID,值为 0。组 ID (GID) 0超级用户所属的主组 ID。 用户描述 root用户的描述信息,这里是简单的 “root”。 主目录 /root超级用户的主目录路径。 登录 Shell /bin/bash超级用户登录后使用的默认 Shell。
passwd命令:用户修改用户密码
passwd # 管理员用户可以修改其他用户密码,普通用户只能修改当前用户密码
显示账户密码相关信息
passwd -S root
# root PS 1969-12-31 0 99999 7 -1 (Password set, SHA512 crypt.)

示例:
passwd user1 # root 用户修改 user1 的密码
passwd -d wuhs #删除指定用户密码
passwd -l wuhs # 锁定用户
passwd -u wuhs # 解锁用户
删除用户
1
userdel [-r] xxx
| 命令 | 效果 |
|---|---|
userdel testuser |
删除用户账户,保留家目录和邮件池。 |
userdel -r testuser |
删除用户账户、家目录和邮件池,彻底清除用户相关数据。 |
相关用户属性
切换用户 su
1
bsu + 用户名
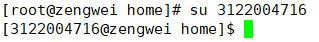
体验管理员 sudo
1
sudo + 命令 # 当前命令由管理员权限执行
打包与压缩
归档(Archiving)
- 描述: 归档,也称为打包,是指将多个文件或目录合并成一个单独的文件,便于存储、备份和传输。归档文件本身不经过压缩,所以其大小基本上是其中所有文件和目录大小的总和。
- 目的: 主要是为了方便管理多个文件,减少文件数量。
- 举例: 想象一下,你有100张照片要分享给朋友。与其一张张发送,不如将这100张照片打包成一个
.tar归档文件,然后发送给朋友,这样朋友只需要下载一个文件即可。
压缩(Compression)
- 描述: 压缩是指通过特定的算法,减小文件占用的存储空间。压缩的原理通常是查找文件中的重复模式,并用更短的代码来表示这些模式,从而达到缩减文件大小的目的。
- 目的: 节省存储空间,加快文件传输速度。
- 举例: 你有一个 100MB 的视频文件,使用压缩软件将其压缩成 50MB,这样你就可以用更短的时间上传或下载这个文件,同时也能节省一半的存储空间。
Linux 下常见的压缩包类型
| 格式 | 压缩工具 | 描述 |
|---|---|---|
.zip |
zip |
一种常见的压缩格式,在 Windows、macOS 和 Linux 系统中都广泛使用。压缩和解压速度较快,但压缩率通常不如其他格式。 |
.gz |
gzip |
gzip 主要用于压缩单个文件。压缩后会删除源文件(通常与 tar 命令配合使用)。 |
.tar |
tar |
仅用于归档,不进行压缩。常与其他压缩工具(如 gzip、bzip2、xz)结合使用,形成 .tar.gz、.tar.bz2、.tar.xz 等压缩包。 |
.bz2 |
bzip2 |
bzip2 的压缩率比 gzip 高,但压缩和解压速度较慢。 压缩后会删除源文件(通常与 tar 命令配合使用)。不太常用。 |
.tar.gz |
tar + gzip |
先使用 tar 命令进行归档打包,然后使用 gzip 进行压缩。这是 Linux 系统中最常见的压缩格式之一。 |
.tar.bz2 |
tar + bzip2 |
先使用 tar 命令进行归档打包,然后使用 bzip2 进行压缩。压缩率比 .tar.gz 高,但速度较慢。 |
.tar.xz |
tar + xz |
先使用 tar 命令进行归档打包,然后使用 xz 进行压缩。xz 具有很高的压缩率,但压缩和解压速度通常是最慢的,适合对压缩率要求较高的场景。 |
tar 命令
-
基本语法:
tar [选项] [归档文件名] [要归档的文件或目录] - 常用选项:
-c:创建新的归档文件。-x:从归档文件中提取文件(解包)。-t:列出归档文件中的文件列表,而不实际解压文件。-v:在终端输出归档或解包的详细过程。-f:指定归档文件的名称。注意:-f选项必须放在所有选项的最后面,后面紧跟归档文件名。-z:使用gzip压缩归档后的文件(.tar.gz)。-j:使用bzip2压缩归档后的文件(.tar.bz2)。-J:使用xz压缩归档后的文件(.tar.xz)。-C <目录>:指定解压到的目录。如果目录不存在,需要先创建。--exclude=<文件名或目录名>:排除指定的文件或目录。可以使用多个--exclude选项来排除多个文件或目录。-h:打包软链接本身,而不是软链接指向的实际文件。如果不使用此选项,tar 会打包软链接指向的实际文件。
-
示例
打包文件
tar -cvf xxx.tar xxx/打包并压缩一个文件
tar -zcvf xxx.tar.gz xxx/解压文件
# 解压到当前目录 tar -xvf xxx.tar # 解压到指定目录 目录要存在 tar -xvf xxx.tar -C xxx/看看包里面的内容
tar tf xxx.tar注:压缩和解压的命令,只需要将c换成x即可
zip 命令
-
注意: 默认情况下,Linux 系统可能没有安装
zip和unzip工具,需要手动安装。1 2 3 4 5 6
# 对于 Debian/Ubuntu 系统: sudo apt-get update sudo apt-get install zip unzip # 对于 CentOS/RHEL/Fedora 系统: sudo yum install zip unzip -y
-
使用示例:
-
压缩文件:
1 2
zip myarchive.zip myfile.txt # 将 myfile.txt 压缩成 myarchive.zip -
压缩目录:
1 2
zip -r myarchive.zip mydirectory/ # 将 `mydirectory` 目录及其内容递归地压缩成 `myarchive.zip`
-
查看压缩包内容:
1 2 3
unzip -l myarchive.zip # 列出压缩包中的文件列表 zipinfo myarchive.zip # 功能类似 `unzip -l`, 提供更详细的信息 unzip -t myarchive.zip # 测试压缩包的完整性
-
解压压缩包:
1 2 3 4
unzip myarchive.zip # 将 myarchive.zip 解压到当前目录 unzip myarchive.zip -d /opt/myfiles # 将 `myarchive.zip` 解压到 /opt/myfiles # 目录. 如果该目录不存在,unzip 会自动创建)
-
总结
tar命令主要用于归档,可以将多个文件和目录合并成一个文件。gzip、bzip2和xz命令用于压缩,可以减小文件的大小。通常与tar命令结合使用,形成.tar.gz、.tar.bz2和.tar.xz等压缩包。zip命令是一种常见的压缩工具,可以压缩文件和目录,并且在不同的操作系统中都兼容。
重定向,管道
重定向
I/O重定向允许我们将命令的输入和输出重定向到文件中
输出重定向
标准错误是不能通过这个方式的
-
覆盖添加
1
echo abc > a.txt # 将 abc 字符串覆盖写入 a.txt
-
追加添加
1
echo 123 >> a.txt # 将 abc 字符串追加写入 a.txt

注:以上只能将标准输出重定向到文件中,标准出错是不能通过此方式输出到文件
只需要在后面加上 2>&1 即可
./xxx> test.log 2>&1
>:将命令的标准输出重定向到指定文件。会覆盖文件原有内容。>>: 将命令的标准输出重定向到指定文件。会追加到文件末尾。2>:将命令的标准错误输出重定向到指定文件。同样会覆盖文件原有内容。2>>: 将命令的标准错误输出重定向到指定文件。会追加到文件末尾。&1:&符号在这里表示文件描述符的引用,而不是一个普通的文件名。&1代表标准输出(STDOUT)的文件描述符。
./xxx: 执行当前目录下的可执行文件xxx。> test.log: 将xxx命令的标准输出 (STDOUT) 重定向到文件test.log中。 如果test.log文件不存在,则创建它;如果存在,则覆盖其原有内容。 现在,所有原本应该显示在屏幕上的正常输出信息,都会被写入到test.log文件中。2>&1: 这是一个关键的部分。它的作用是:2>: 将标准错误输出 (STDERR) 进行重定向。&1: 将标准错误输出重定向到与标准输出相同的位置。 因为之前标准输出已经被重定向到test.log,所以这里实际上是将标准错误输出也重定向到test.log。
输入重定向
查看文件内容
cat < data.txt # 效果基本同 cat data.txt

创建多行文本
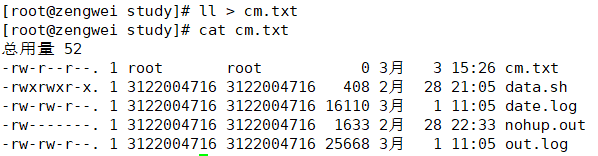
$ cat << EOF > cm.txt
> Hello, this is a custom message!
> 你好
> EOF
- EOF 表示,以 EOF 作为结束(可以是容易字符串)
- 写入 cm.txt
- cat 输出

管道
Linux所提供的管道符“|”将两个命令隔开
管道符左边命令的输出就会作为管道符右边命令的输入
连续使用管道意味着第一个命令的输 出会作为 第二个命令的输入,第二个命令的输出又会作为第三个命令的输入,依此类推
例如查看文件的行数
cat xxx.txt | wc -l
就是将 cat xxx.txt的输出作为wc -l 的输入

xargs命令
有些命令不支持管道符来传递参数,xargs 可以将标准输入转换为命令行参数。
比如: 搜索/etc目录下的所有”.conf”结尾的文件信息,然后以详细列表形式显示
find /etc -name "*.conf" | ls -l # 不支持
-
在
/etc目录下查找所有以.conf结尾的文件。 -
输出结果是一个文件路径列表,每行一个路径:
1 2 3 4
/etc/adduser.conf /etc/apparmor/local/site.conf /etc/fonts/fonts.conf ...
- 管道符
|将find命令的输出(文件路径列表)作为标准输入传递给ls -l。 - 但是,
ls -l命令不会处理标准输入,它只会列出当前目录下的文件信息(默认是当前工作目录)。 - 因此,
ls -l会忽略管道传递过来的内容,直接列出当前目录的文件信息。
可以通过xargs就可以实现这个功能,xargs 会将标准输入的内容(文件路径列表)转换为命令行参数,传递给 ls -l。
find /etc -name "*.conf" | xargs ls -l
- -p 当每次执行一个argument的时候询问一次用户。
- -i 将xargs的每项名称,一般是一行一行赋值给 {},可以用 {} 代替。
cat cm.txt | xargs echo
# `xargs` 会将多行内容合并为一行,并用空格分隔,然后传递给 `echo`。
cat cm.txt | xargs -i echo {}
# -i 选项的作用是将输入内容替换到 {} 的位置。如果命令中没有 {},xargs 不知道将输入内容插入到哪里。
| 命令 | 输出依据 | 特点 |
|---|---|---|
cat cm.txt |
原样输出文件内容 | 直接输出文件内容,不做任何处理。 |
cat cm.txt |
xargs echo |
将多行内容合并为一行,用空格分隔 |
cat cm.txt |
xargs -i echo {} |
逐行输出文件内容 |
cat cm.txt |
xargs -i echo |
输出空行 |

grep
grep是一个可以利用”正则表达式”进行”全局搜索”的工具,grep会在文本文件中按照指定的正则进行全局搜索,并将搜索出的行打印出来。
参数
-A<显示列数> 除了显示符合范本样式的那一行之外,并显示该行之后的内容。
-b 在显示符合范本样式的那一行之外,并显示该行之前的内容。
-c 计算符合范本样式的列数。
-C<显示列数>或-<显示列数> 除了显示符合范本样式的那一列之外,并显示该列之前后的内容。
-d<进行动作> 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep命令将回报信息并停止动作。
-e<范本样式> 指定字符串作为查找文件内容的范本样式。
-E 将范本样式为延伸的普通表示法来使用,意味着使用能使用扩展正则表达式。
-f<范本文件> 指定范本文件,其内容有一个或多个范本样式,让grep查找符合范本条件的文件内容,格式为每一列的范本样式。
-F 将范本样式视为固定字符串的列表。
-G 将范本样式视为普通的表示法来使用。
-h 在显示符合范本样式的那一列之前,不标示该列所属的文件名称。
-H 在显示符合范本样式的那一列之前,标示该列的文件名称。
-i 忽略字符大小写的差别
-v 反转查找。
测试文件 texttxt.txt
I aaam teacher
I aaaaaam student
I like Linux
I like JAVA
Hello World
世界,你好!
12312434
324828
fdjsoifjidosa
joijofids.
joijiodsf.
#jidfjisoaf
#fjidsfoijsdaifo
普通搜索
grep "JAVA" testtxt.txt
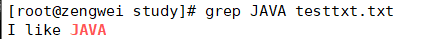
不区分大小写
grep -i "L" testtxt.txt

输出i开头,并且不区分大小写的行
grep -i "^i" testtxt.txt

-n 代表显示匹配行和行号

打印匹配前后的行
# 打印匹配行前两行 before
grep Linux testtxt.txt -n -B2
# 打印匹配行后两行 after
grep Linux testtxt.txt -n -A2
# 打印匹配行前后两行
grep Linux testtxt.txt -n -C2
使用 -c 选项即可只统计符合条件的总行数,而不会打印出行。
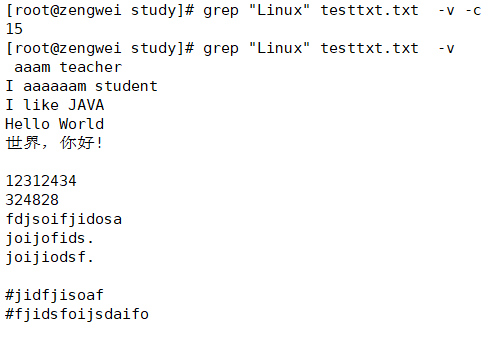
grep "Linux" testtxt.txt -c
排除匹配的行
grep "Linux" testtxt.txt -v
匹配空行
grep "^$" testtxt.txt -n


”.”点表示任意一个字符,有且只有一个, 不包含空行
grep "2.." testtxt.txt -n

“*“表示找出前一个字符0次或一次以上
grep "12*" testtxt.txt -n
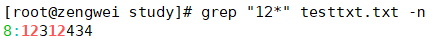
1:匹配字符 “1”。2*:匹配零个或多个 “2”。
”.*“表示匹配同一行内的任意字符
grep "12.*34" testtxt.txt -n
# 同一行内,存在[12*34] 的行
跨行匹配使用 -Pz 或者 -Pzo
| -Pz | -Pzo |
|---|---|
| 打印包含匹配项的 “行”(直到下一个 null 字符)。 | 只打印匹配到的文本本身。 |
[abc]表示匹配中括号中任意一个字符,a或b或c,常见的形式如下
- [a-z]匹配所有小写单个字母[A-Z]匹配所有单个大写字母
- [a-zA-Z]匹配所有的单个大小写字母
- [0-9]匹配所有单个数字
- [a-zA-ZO-9]匹配所有数字和字母
grep "[abc]" testtxt.txt -n

扩展正则表达式
在使用-E选项时,grep才支持扩展正则表达式,不使用-E选项时,grep默认只支持 基本正则表达式。
grep -E "H?ello" testtxt.txt -n

和管道符联用:在限定范围内搜索
cat testtxt.txt | grep -E "H?ello" -n
ps aux | grep bash -n

软件安装
linux安装软件的三种方式
1.rpm安装 用于离线安装
2.yum安装 用于大部分的在线安装
3.源代码编译安装
yum
YUM是“Yellow dog Updater, Modified”的缩写,是一个软件包管理器,YUM从指定的地方自动下载RPM包并且安装,能够很好的解决依赖关系问题
基本安装
yum install 软件名
yum install 软件名 -y # 自动确认
常见用法表
| 命令 | 功能 |
|---|---|
| yum check-update | 检查可更新的所有软件包 |
| yum update | 下载更新系统已安装的所有软件包 |
| yum upgrade | 大规模的版本升级,与yum update不同的是,连旧的被淘汰的包也升级 |
| yum install | 安装软件包 |
| yum update | 更新指定软件包 |
| yum remove | 移除指定软件包 |
| yum localinstall | 安装本地的RPM包(与rpm -i命令不同,可同时安装依赖的包) |
| yum localupdate | 更新本地的RPM包(与rpm -U命令不同,可同时安装依赖的包) |
| yum list | 列出资源库中所有可以安装或更新的rpm包,以及已经安装的rpm包 |
| yum search | 检测所有可用的软件的名称,描述,概述和已列出的维护者,查找与正则表达式匹配的值 |
yum换源
Linux系统默认的yum源是国外的,下载时速度非常慢,或者有些软件无法下载。所以要更换yum源来加快软件下载速度。
手动换源
#安装wget软件 如果没有安装wget命令
yum install -y wget
#备份旧的yum源
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
#下载新的yum源
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
#更新yum缓存
yum clean all
yum makecache
使用第三方工具换源
#安装yum-utils
yum -y install yum-utils
#更改yum源
yum-config-manager --add-repo http://mirrors.aliyun.com/repo/Centos-7.repo
#更新yum缓存
yum makecache
常见的yum源
# 阿里云
http://mirrors.aliyun.com/repo/Centos-7.repo
# 清华大学
http://mirrors.tuna.tsinghua.edu.cn/help/centos/
# 163
http://mirrors.163.com/.help/CentOS7-Base-163.repo
删除软件
检查软件包是否存在
yum list installed | grep <packagename>
删除软件包
yum remove <packagename>
卸载依赖包
yum autoremove
强制卸载
yum remove <packagename> –nodeps
离线安装
首先我们需要在可以上网的服务器上将需要安装软件的rpm离线包下载下来,然后拷贝到不能上网的服务器上安装
例如下载pkg的rpm包
yum install --downloadonly --downloaddir=./pkg vim
然后离线安装
yum localinstall pkg/vim-enhanced-7.4.629-8.el7_9.x86_64.rpm
环境变量
按生效的范围分类
-
系统环境变量:公共的,对全部的用户都生效。
-
用户环境变量:用户私有的、自定义的个性化设置,只对该用户生效。
**按生存周期分类 **
-
永久环境变量:在环境变量脚本文件中配置,用户每次登录时会自动执行这些脚本,相当于永久生效。
-
临时环境变量:使用时在Shell中临时定义,退出Shell后失效。
查看环境变量
env # 查看全部环境变量
echo $环境变量名 # 查看某个变量值
常用的环境变量
PATH 可执行程序的搜索目录
LANG Linux 系统的语言、地区、字符集
HOSTNAME 服务器的主机名
SHELL 用户当前使用的Shell解析器
USER 当前登录用户的用户名
HOME 当前登录用户的主目录
PWD 当前工作目录
设置临时环境变量
变量名='值'
export 变量名
或export 变量名='值'
如果环境变量的值没有空格等特殊符号,可以不用单引号包含。
示例:
export ORACLE_HOME=/oracle/home
export ORACLE_BASE=/oracle/base
export ORACLE_SID=snorcl11g
export NLS_LANG='Simplified Chinese_China.ZHS16GBK'
export PATH=$PATH:$HOME/bin:$ORACLE_HOME/bin:.
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$ORACLE_HOME/lib:.
采用export设置的环境变量,在退出Shell后就会失效,下次登录时需要重新设置
如果希望环境变量永久生效,需要在登录脚本文件中配置:
a. 系统环境变量
对于所有用户来说,都会在每次登录时生效,设置系统环境变量有三种方法
-
在
/etc/profile文件中设置(不推荐)用户登录时执行
/etc/profile文件中设置系统的环境变量。但是,Linux不建议在/etc/profile文件中设置系统环境变量。- 要立即生效,输入
source /etc/profile
- 要立即生效,输入
-
在
/etc/profile.d目录中增加环境变量脚本文件,这是Linux推荐的方法。查看此目录:

/etc/profile在每次启动时会执行/etc/profile.d下全部的脚本文件。/etc/profile.d比/etc/profile好维护,不想要什么变量直接删除/etc/profile.d下对应的 shell 脚本即可例如:增加一个启动时输出字符串
1 2
vim /etc/profile.d/hello.sh echo -e "Hello! Welcome to Centos 7.\nGood day!"
-
在
/etc/bashrc文件中设置环境变量该文件配置的环境变量将会影响全部用户使用的bash shell。但是,Linux也不建议在
/etc/bashrc文件中设置系统环境变量
b. 用户环境变量
只对当前用户生效的环境变量;
在用户的主目录,有几个特别的文件,用 ls 是看不见的,用 ls .bash_* 可以看见。
-
.bash_profile (推荐首选)
当用户登录时执行,每个用户都可以使用该文件来配置专属于自己的环境变量。
-
.bashrc
当用户登录时以及每次打开新的 Shell 时该文件都将被读取,不推荐在里面配置用户专用的环境变量,因为每开一个 Shell,该文件都会被读取一次,效率肯定受影响。
-
.bash_logout
当每次退出系统(退出 bash shell)时执行该文件。
-
.bash_history
保存了当前用户使用过的历史命令。
c. PATH 环境变量
echo $PATH 查看当前值:

# 冒号作为分隔
不在 PATH环境变量 中的路径下的程序只能通过 ./xxx 执行,当然,环境变量中加入 ./ 即可方便执行。

环境变量的生效
在Shell下,用export 设置的环境变量对当前 Shell 立即生效,Shell 退出后失效。
在脚本文件中设置的环境变量不会立即生效,退出Shell 后重新登录时才生效,或者用source 命令让它立即生效,例如:
1
source /etc/profile
网络相关
配置主机名
-
编辑配置文件
cat /etc/hostname重启之后生效
-
使用hostname命令修改
1
hostname newhostname重新登录生效
-
使用hostnamectl命令修改(有的没这个命令)
hostnamectl set-hostname adminthy重新登录生效
配置网卡信息
查看当前网卡(ens33):
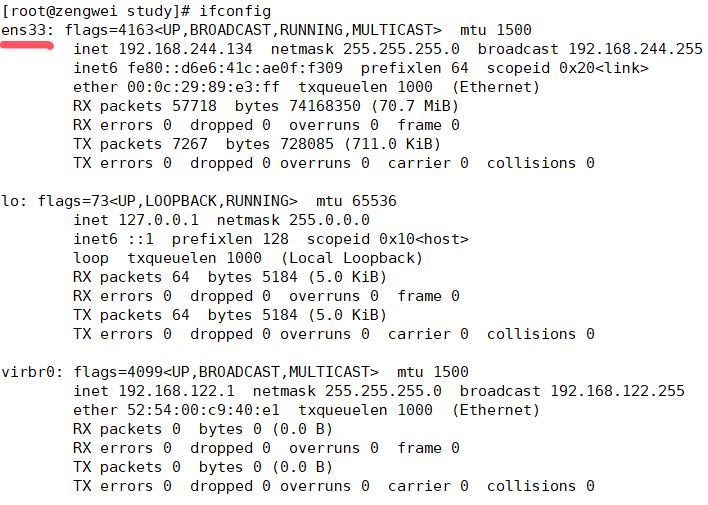
网卡配置信息 /etc/sysconfig/network-scripts/ifcfg-eth0–> eth0 改成 ens33
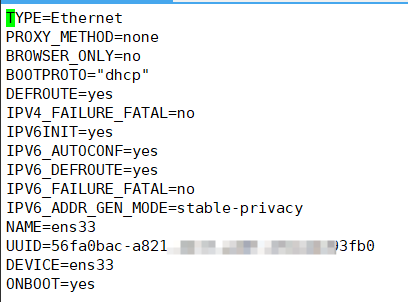
目前是 “dhcp”自动获取ip地址,如果需要配置静态IP(主机IP变动时,虚拟机就无法联网):
DEVICE=eth0 # 网卡名称
HWADDR=00:0c:29:b7:75:b9 # Mac地址
TYPE=Ethernet # 网络类型
UUID=f859baff-38d0-4987-b9e1-1f861ab87a00 # 磁盘唯一标识
ONBOOT=yes # 是否自启动网卡
NM_CONTROLLED=yes
BOOTPROTO=static # <修改>网卡获取IP方式
IPADDR=10.0.0.200 # <修改>IP地址
NETMASK=255.255.255.0 # <修改>子网掩码
GATEWAY=10.0.0.2 # <修改>网关
DNS1=1.1.1.1 # <修改>DNS地址
USERCTL=no
PEERDNS=yes
IPV6INIT=no
ip地址获取方式
none:引导时不适用协议
static:静态分配IP地址
DHCP:自动获取IP地址
修改完之后,重启网卡就可以生效了
使配置文件生效,重启单个网卡:
ifdown eth0 && ifup eth0
重启所有网卡:
/etc/init.d/network restart
测试网络连通性
ping
使用ping可以很直观的发现目标是否可达
-
如果是ping域名没反应,可能是域名写错了,也可能是dns的问题
-
如果ping ip半天出不来数据 那就是主机不在线,看看是不是没开机,或者网卡掉了
-
但是会有特殊情况,就是主机可能禁ping,web访问却可以
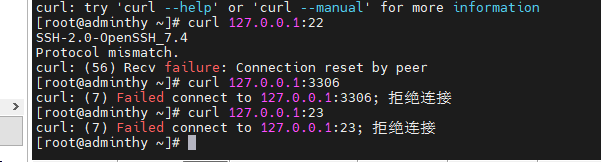
curl
一般可以用这个检测端口是否开放
不仅是用于web的端口检测,22,3306,6379这些端口同样可以检测
端口开了和没开响应是不一样的

tcpdump
前面两个就可以检测常见的网络连接情况
再高级一点的就是使用网络抓包工具,抓流量数据去看
netstat
这个一般是在目标主机上使用的,一个端口没开,先看看这个主机上是不是开了这个端口
netstat -ntlp | grep 22
防火墙
也是在目标主机上使用
可能是服务器端口没放行
firewalld命令
#启动/关闭firewall
systemctl start/stop firewalld
#查看防火墙状态
systemctl status firewalld
#禁用或者启用
systemctl disable/enable firewalld
#查看 firewall目前开放的内容
firewall-cmd --list-all
查看端口是否开放
firewall-cmd --query-port=8020/tcp

开放/关闭端口
firewall-cmd --add-port=5000/tcp --permanent
#或
firewall-cmd --permanent --zone=public --add-port=8080/tcp
#–zone #作用域
#–add-port=8080/tcp #添加端口,格式为:端口/通讯协议
#–permanent #永久生效,没有此参数重启后失效
firewall-cmd --reload # 配置立即生效
# 要关闭一个之前打开的端口,可以使用 --remove-port 选项。 命令格式如下:
firewall-cmd --remove-port=<端口号>/<协议> --permanent
# 例如,要关闭 5000 端口的 TCP 访问,可以执行以下命令:
firewall-cmd --remove-port=5000/tcp --permanent
# 要关闭 8080 端口 (public zone):
firewall-cmd --permanent --zone=public --remove-port=8080/tcp
查看开放的端口
firewall-cmd --list-port
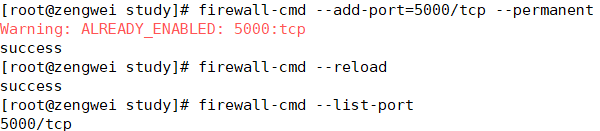
参考
B站up主“枫枫知道”:https://www.bilibili.com/video/BV1sc411v7J4